Introduction to Language Models

If you have used ChatGPT, Claude, or Gemini even once, you have already interacted with a Large Language Model. But what exactly is happening behind the scenes when these models generate text that feels almost human?
In this lesson, we will break down language models from the ground up. Whether you are a complete beginner curious about AI or a developer looking to build applications with LLMs, this foundation will serve you well.
What You Will Learn
- What language models actually are and how they work at a fundamental level
- The evolution from simple statistical models to modern neural networks
- Key milestones that shaped today's LLM landscape
- How attention mechanisms revolutionized language understanding
- When LLMs make sense for your projects (and when they do not)
- Practical considerations for choosing and deploying models
What is a Language Model?
At its core, a language model is a system that predicts the probability of a sequence of words. Think of it like this - when you type "The weather today is" on your phone, it suggests words like "good", "bad", or "sunny". That suggestion system is a very basic language model.
The Mathematical Foundation
The mathematical foundation is straightforward. Given a sequence of words, a language model calculates:
plaintextP(word_n | word_1, word_2, ..., word_n-1)
In plain terms: what is the probability of the next word, given all the previous words?
Modern LLMs like GPT-4 or Claude take this concept and scale it massively. They are trained on billions of text samples and have learned patterns in language that allow them to generate logically connected, clear, consistent and contextual responses.
A Deeper Example
Consider the sentence: "I drink chai every ___"
A language model might predict:
- "morning" - 45% probability
- "day" - 30% probability
- "evening" - 10% probability
- "hour" - 8% probability
- Other words - 7% combined
The model picks based on these probabilities. But here is where it gets interesting: the model does not just pick the highest probability word every time. There is randomness (controlled by something called "temperature") built into the selection process.
Understanding Temperature
Temperature is a parameter that controls randomness in the model's predictions:
Low temperature (0.0 - 0.3): The model becomes deterministic, almost always choosing the highest probability word. Great for factual tasks, code generation, or when you need consistency.
Medium temperature (0.4 - 0.7): Balanced creativity and coherence. Good for most applications like chatbots, content generation, and general assistance.
High temperature (0.8 - 1.5+): More creative and unpredictable outputs. Useful for brainstorming, creative writing, or generating diverse options.
Example with prompt: "The sunset was"
- Temperature 0.2: "beautiful" (picks most common continuation)
- Temperature 0.7: "breathtaking" (more varied, still coherent)
- Temperature 1.2: "a symphony of crimson whispers" (creative, potentially odd)
The Evolution: From N-grams to Transformers
Now that we understand what language models do, let's trace how they evolved. This history isn't just academic—understanding the limitations of earlier approaches helps explain why modern LLMs work so well and where they still struggle.
Statistical Language Models (1990s-2000s)
The earliest language models used n-grams - they looked at sequences of n words and counted how often different words followed them in training data.
How N-grams Work:
A trigram model (n=3) learns by counting sequences in its training data:
- "I want to eat pizza" appears 20 times
- "I want to go home" appears 15 times
- "I want to sleep now" appears 10 times
After seeing 100 instances of "I want to", the model learns:
- "eat" follows 20% of the time
- "go" follows 15% of the time
- "sleep" follows 10% of the time
- Other words: 55% combined
The Critical Problem:
N-gram models have no understanding of context beyond a few words. Consider:
"The bank by the river was beautiful. I needed to deposit money at the ___"
An n-gram model looking at only "money at the" has no idea we are talking about a financial institution, not a river bank. It cannot capture long-range dependencies or semantic meaning.
Neural Language Models (2010s)
The breakthrough came when researchers started applying neural networks to language. In 2013, Tomas Mikolov and colleagues at Google published Word2Vec, demonstrating that words could be represented as vectors in a mathematical space where similar words naturally cluster together.
Word Embeddings Explained:
Instead of treating words as discrete symbols, neural models represent them as points in high-dimensional space (typically 300-1000 dimensions). Words with similar meanings end up close together:
- "king" - "man" + "woman" ≈ "queen" (the famous example)
- "Paris" - "France" + "Germany" ≈ "Berlin"
- "Apple" - "fruit" + "company" ≈ "Google"
This was revolutionary because the model learns that "happy" and "joyful" are similar, even if they never appear together in training.
RNNs and LSTMs
Then came Recurrent Neural Networks (RNNs) and LSTMs (Long Short-Term Memory networks). These could process sequences and remember information over longer contexts.
The Analogy: Imagine reading a book while trying to summarize it in one sentence. With each new paragraph, you update your mental summary—but you can only hold so much in your head. By chapter 10, you have forgotten the details of chapter 1. That is exactly how RNNs work.
How RNNs Work:
RNNs process text sequentially, maintaining a "hidden state" (like your mental summary) that gets updated with each word:
python# Conceptually, RNNs process text like this: hidden_state = initial_state # Your empty mind for word in sentence: hidden_state = update(hidden_state, word) # hidden_state now "summarizes" all previous words output = predict(hidden_state)
The Problem: Basic RNNs suffered from "vanishing gradients"—information from early words would fade away, like trying to remember the first page of a novel by the time you reach the end.
LSTMs: The Fix
LSTMs (Long Short-Term Memory) added a clever solution: gates that control what to remember and what to forget.
Think of it like having a notebook while reading:
- Forget gate: "This detail is no longer relevant, cross it out"
- Input gate: "This is important, write it down"
- Output gate: "What from my notes is relevant right now?"
This allowed LSTMs to maintain information over hundreds of words—a huge improvement over basic RNNs.
But Still Limited:
- Training was slow—you could not parallelize across words (must read word 1 before word 2)
- Even LSTMs struggled with very long contexts (1000+ words)
- No selective attention—every word updated the same hidden state
The Transformer Revolution (2017)
The limitations of RNNs led researchers at Google to ask: what if we could process all words at once instead of sequentially? The answer came in the now-famous paper "Attention Is All You Need" by Vaswani et al.
The Transformer architecture introduced self-attention—a mechanism that lets the model look at all words in a sequence simultaneously and determine which ones are most relevant to each other. This single innovation changed everything.
What is Self-Attention?
Imagine reading this sentence: "The animal didn't cross the street because it was too tired."
As a human, you instantly know that "it" refers to "animal", not "street". You do this by attending to the relationship between words. Self-attention lets neural networks do the same thing.
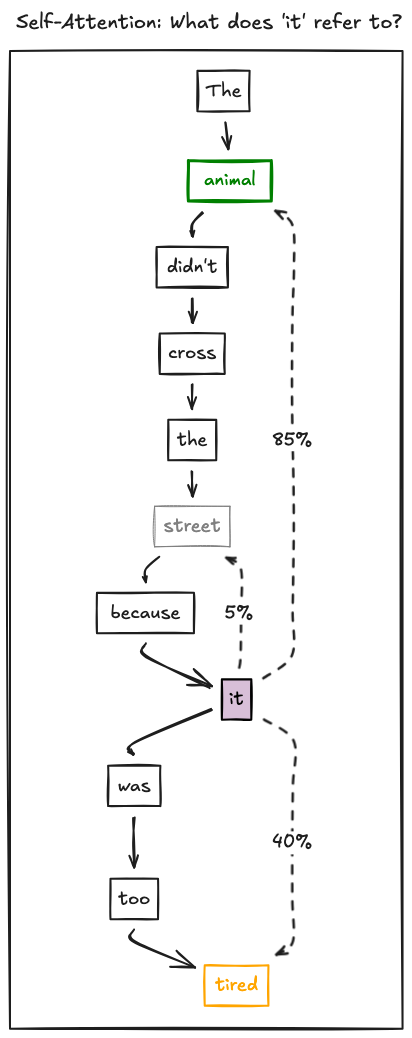
How Self-Attention Works:
For each word in a sequence, the model:
- Looks at every other word in the sentence
- Calculates relevance scores - how much should I pay attention to each word?
- Creates a new representation that combines information from relevant words
When processing "it" in our example:
- High attention to "animal" (85%)
- Low attention to "street" (5%)
- Medium attention to "tired" (40%)
- This helps the model understand the reference
Why Transformers Changed Everything
The Transformer architecture was revolutionary for three reasons:
1. Parallel Processing
Unlike RNNs that process words one-by-one, Transformers process all words at once. On modern GPUs, this means:
- Training is 10-100x faster
- You can use much larger datasets
- Scaling becomes economically feasible
2. Long-Range Dependencies
Self-attention can connect words that are hundreds of tokens apart. The model can understand that a pronoun on line 50 refers to a name on line 1.
3. Scalability
The architecture scales beautifully. Add more layers, more attention heads, more parameters - and performance keeps improving (with enough data).
GPT and the Era of Large Language Models (2018-Present)
With Transformers solving the parallelization problem, the race to scale began. OpenAI's GPT (Generative Pre-trained Transformer) took the transformer decoder architecture and asked a simple question: what happens if we just make it bigger?
The answer, documented in their GPT-3 paper, was surprising: a remarkably simple two-step approach could produce models that seemed to "understand" language:
The Two-Step Training Process
Step 1: Pre-training (Unsupervised Learning)
- Train on massive amounts of text from the internet
- Task: Predict the next word
- Result: The model learns grammar, facts, reasoning patterns, and even some biases
Step 2: Fine-tuning (Supervised Learning)
- Train on human-curated examples of desired behavior
- Use techniques like RLHF (Reinforcement Learning from Human Feedback)
- Result: The model learns to follow instructions, be helpful, and avoid harmful outputs
The Scale Revolution
- GPT-2 (2019): 1.5 billion parameters
- GPT-3 (2020): 175 billion parameters
- GPT-4 (2023): Rumored 1+ trillion parameters with mixture-of-experts
What is a Parameter?
Let's understand parameters through an analogy. Imagine you are learning to recognize cats in photos. Your brain adjusts millions of tiny "settings" - what shape are the ears? How pointy? What about the eyes? The whiskers? Each of these settings is like a parameter.
A parameter is simply a number that the model adjusts during training to get better at its task.
Here is a example of what happens inside a language model:
plaintextTask: Predict the next word after "The cat sat on the ___" Before training (random parameters): "mat" → 12% chance "dog" → 11% chance "cloud" → 10% chance (every word has roughly equal probability) After training on millions of sentences: "mat" → 45% chance ← parameter adjusted UP (common pattern!) "floor" → 25% chance ← parameter adjusted UP "dog" → 0.1% chance ← parameter adjusted DOWN (cats don't sit on dogs) "cloud" → 0.01% chance ← parameter adjusted DOWN (physically impossible)
Training is the process of adjusting billions of these numbers until the model makes sensible predictions.
Why do more parameters help?
| Parameters | What it can learn | Real-world analogy |
|---|---|---|
| 1 million | Basic patterns | Recognizing "cat" vs "dog" |
| 1 billion | Complex relationships | Understanding that "it" refers to "cat" |
| 100 billion | Nuanced reasoning | Explaining why cats land on their feet |
The trade-off: More parameters = smarter model, but also more expensive to train and run.
The Key Insight: Scale Matters
The surprising discovery was that scaling follows predictable laws:
10x more parameters + 10x more data + 10x more compute = consistent performance improvement
This held true across orders of magnitude, leading to the "bigger is better" race we see today.
However, we are now seeing interesting patterns:
- Emergent abilities: Models suddenly gain capabilities (like arithmetic or coding) at specific size thresholds—abilities that smaller models completely lack
- Diminishing returns: Going from 100B to 1T parameters costs exponentially more for incrementally smaller gains
The Current Landscape
So where does all this history leave us today? The LLM ecosystem has matured into two distinct camps, and understanding the trade-offs between them is crucial for making practical decisions.
Closed-Source Models
These are API-only models where you cannot access the weights. You send requests over the internet and receive responses.
| Model | Provider | Key Strengths | Context Window |
|---|---|---|---|
| GPT-4o | OpenAI | Reasoning, coding, multimodal, fast | 128K tokens |
| Claude 3.5 Sonnet | Anthropic | Long context, safety, analysis, writing | 200K tokens |
| Gemini 1.5 Pro | Multimodal, extremely long context | 2M tokens |
When to use:
- Production applications requiring reliability
- When you need support and SLAs
- Do not want to manage infrastructure
- Need latest capabilities immediately
- Working with sensitive data (providers offer enterprise options)
Costs (subject to change):
- Pay per token (input + output)
- GPT-4o: ~$5/million input tokens, ~$15/million output tokens
- Claude Sonnet: ~$3/million input tokens, ~$15/million output tokens
- Costs add up quickly at scale
- Note: AI pricing changes frequently—always check official pricing pages
Open-Source Models
These give you full access to model weights. You can download, modify, and run them anywhere.
| Model | Provider | Parameters | Notable Features |
|---|---|---|---|
| Llama 3.1 | Meta | 8B, 70B, 405B | Strong reasoning, multilingual |
| Mistral / Mixtral | Mistral AI | 7B, 8x7B MoE | Efficient, good for EU users |
| Qwen 2.5 | Alibaba | 0.5B to 72B | Excellent for Asian languages |
| Phi-3 | Microsoft | 3.8B | Small but capable |
When to use:
- Need customization or fine-tuning for specific domains
- Data privacy is critical (healthcare, legal, financial)
- Cost control at scale (hosting < API costs after certain volume)
- Want to experiment with model architecture
- Building specialized applications
Costs (subject to change):
- Initial: GPU infrastructure (cloud or on-prem)
- Ongoing: Compute costs (AWS/GCP: $1-10/hour depending on GPU)
- Engineering: Time to set up, optimize, and maintain
When Should You Use LLMs?
With great power comes great responsibility—and great cost. LLMs are genuinely transformative for some problems, but they're expensive overkill for others. Here's a practical framework to help you decide.
Excellent Use Cases
1. Text Generation & Transformation
- Content drafting: Blog posts, marketing copy, documentation
- Summarization: Condensing long documents, meeting notes
- Translation: Between languages, or technical to simple language
- Style transfer: Formal to casual, rewriting for different audiences
Example: Klarna, the Swedish fintech company, reported their AI assistant now handles two-thirds of customer service chats, doing the work equivalent of 700 full-time agents.
2. Code Assistance
- Writing boilerplate code
- Explaining complex code
- Debugging and suggesting fixes
- Generating tests
Example: GitHub reports that developers using Copilot complete tasks 55% faster on average. Many teams use it primarily for generating boilerplate and test code.
3. Question Answering (with RAG)
- Customer support chatbots
- Internal knowledge bases
- Document Q&A systems
Example: Thomson Reuters launched CoCounsel, an AI legal assistant built on GPT-4, integrated into Westlaw. Lawyers can ask natural language questions and get relevant case citations in seconds.
4. Classification & Extraction
- Sentiment analysis
- Entity extraction (names, dates, locations)
- Content moderation
- Data structuring from unstructured text
Example: Spotify uses LLMs to analyze podcast transcripts for content classification and to power their "DJ" feature that creates personalized audio streams with AI-generated commentary.
5. Conversational Interfaces
- Virtual assistants
- Interactive tutors
- Creative brainstorming partners
Example: Duolingo's Roleplay feature uses GPT-4 to let users practice conversations with AI characters in realistic scenarios, providing personalized feedback on grammar and vocabulary.
Poor Use Cases (Common Pitfalls)
1. Real-time Factual Accuracy
- Medical diagnosis
- Legal advice
- Financial recommendations
- Current event reporting
Why: LLMs hallucinate - they generate plausible-sounding but incorrect information with confidence. They do not distinguish between what they know and what they are making up.
Real-world failure: A New York lawyer used ChatGPT for legal research and submitted a brief citing six completely fabricated court cases. The lawyer faced sanctions for not verifying the AI's output.
Better approach: Use LLMs to draft, but always verify with authoritative sources. Implement retrieval systems for factual queries.
2. Mathematical Computation
- Complex calculations
- Financial modeling
- Statistical analysis
Why: LLMs approximate patterns; they do not perform actual computation. They might get "2+2=4" right but fail on "13,467 × 891".
Real-world example: Researchers at Apple found that LLMs fail dramatically on math problems when irrelevant information is added. Simply changing names or adding extra context caused accuracy to drop from 94% to 17%.
Better approach: Use actual calculators, code execution, or symbolic math engines. GPT-4 with Code Interpreter works because it executes Python, not because the LLM does math.
3. Deterministic Systems
- Banking transactions and payment processing
- Safety-critical systems (aviation, medical devices)
- Legal compliance and audit trails
Why: Even at temperature 0, LLMs are not 100% deterministic. The same prompt might yield slightly different outputs.
Real-world caution: Air Canada's chatbot incorrectly promised a bereavement discount that didn't exist. A tribunal ruled the airline was liable for the chatbot's hallucinated policy, costing them the refund plus damages.
Better approach: Use rule-based systems, formal verification, or traditional software with deterministic logic.
4. Privacy-Sensitive Data (without safeguards)
- Personal health records (HIPAA-protected data)
- Government identity documents (SSN, national IDs)
- Financial information and credit data
- Trade secrets and proprietary code
Why: LLMs can leak training data patterns. API providers might use your data for improvements (unless you have specific agreements).
Real-world incident: Samsung banned ChatGPT after employees accidentally leaked proprietary source code and internal meeting notes by pasting them into the chatbot for help.
Better approach: Use open-source models on-prem, or ensure strict data usage agreements with API providers. Anonymize data before processing.
The Cost-Benefit Question
The examples above might make LLMs sound like a silver bullet. They're not. Before committing to an LLM-based solution, work through these questions honestly:
1. Can a simpler solution work?
Do not default to LLMs because they are trendy. Consider:
- Regex or keyword matching: If you are just finding patterns like email addresses or dates
- Traditional ML: If you have labeled data and need efficiency (sentiment analysis with a small BERT model)
- Rule-based systems: If logic is well-defined (tax calculations, workflow automation)
Example: A fintech startup wanted an LLM to categorize payment transactions. After analysis, they realized 80% fell into just 5 categories. A simple classifier trained on 500 labeled examples worked better and cost 1/100th as much.
2. What is the cost of errors?
Different applications have vastly different risk profiles:
- Low stakes: Social media captions, marketing brainstorms - hallucinations are annoying but not dangerous
- Medium stakes: Customer support, content moderation - errors frustrate users or need human review
- High stakes: Medical advice, legal documents, financial guidance - errors can cause real harm
Rule of thumb: High-stakes applications need human-in-the-loop verification, which might negate the automation benefits.
3. Do I need the latest model?
GPT-4 is powerful but expensive. Consider:
- GPT-3.5: 10x cheaper, handles 70% of tasks well
- Open-source models: Llama 3.1 8B costs pennies to run and works great for focused tasks
- Fine-tuned smaller models: Often outperform larger general models on specific domains
Example: A company switched from GPT-4 to a fine-tuned Llama 3.1 8B for product description generation. Quality stayed high, costs dropped 95%.
4. What is my data strategy?
LLMs are only as good as their context:
- Zero-shot: Using the model with just a prompt (works for general tasks)
- Few-shot: Providing examples in the prompt (improves accuracy significantly)
- RAG: Retrieving relevant documents and adding to context (best for knowledge-intensive tasks)
- Fine-tuning: Training the model on your specific data (highest quality, highest cost)
Common Misconceptions About LLMs
Before we wrap up, let's clear up some misconceptions that trip up even experienced engineers:
Misconception 1: "LLMs understand language like humans do"
Reality: LLMs are pattern recognition machines. They predict what words should come next based on patterns in training data, not true comprehension.
Implication: They can appear to understand complex concepts but might fail on simple reasoning tasks that require actual understanding.
Misconception 2: "More parameters always mean better performance"
Reality: It depends on your task. A fine-tuned 7B model can outperform GPT-4 on domain-specific tasks.
Implication: Match your model size to your problem. Bigger models cost more and are not always necessary.
Misconception 3: "LLMs can access the internet and retrieve real-time information"
Reality: Base LLMs only know what was in their training data (cutoff date). They cannot browse the web unless given specific tools.
Implication: For current information, you need RAG systems, web search tools, or fine-tuning with recent data.
Misconception 4: "If the LLM says it confidently, it must be true"
Reality: Confidence and correctness are independent. LLMs hallucinate with complete confidence.
Implication: Always verify critical information. The model does not know when it is wrong.
What is Next?
Now that you understand what language models are, how they evolved, and when to use them, we will dive deeper into the architecture that makes modern LLMs possible.
In the next lesson, we will explore:
- The Transformer Architecture in detail
- How attention mechanisms actually work (with math!)
- Why positional encodings matter
- How to read and understand architecture diagrams
- The difference between encoder, decoder, and encoder-decoder models
This foundation will prepare you to understand advanced topics like:
- Fine-tuning strategies
- Prompt engineering best practices
- Building RAG systems
- Evaluating model performance
- Optimizing for production
Key Takeaways
- Language models predict probability distributions over sequences of words
- The evolution went: n-grams → RNNs → Transformers → LLMs
- Self-attention enables parallel processing and long-range understanding
- Temperature controls randomness: low for factual tasks, high for creativity
- Choose between open and closed-source models based on your requirements: cost, privacy, customization
- LLMs excel at generation and transformation but struggle with factual accuracy and deterministic logic
- Always consider simpler solutions first - LLMs are not always the answer
- The cost of errors should dictate your verification strategy
References & Further Reading
Papers Referenced in This Lesson
- Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space - The Word2Vec paper that introduced word embeddings
- Vaswani, A., et al. (2017). Attention Is All You Need - The original Transformer paper
- Brown, T., et al. (2020). Language Models are Few-Shot Learners - GPT-3 paper demonstrating scaling laws
Recommended Next Steps
- The Illustrated Transformer by Jay Alammar - Visual walkthrough, perfect companion to the next lesson
- What Is ChatGPT Doing... and Why Does It Work? by Stephen Wolfram - Accessible deep-dive into how LLMs generate text
- State of GPT by Andrej Karpathy - Excellent video overview of how ChatGPT was trained
For Deeper Understanding
- On the Opportunities and Risks of Foundation Models - Stanford's comprehensive 200-page overview
- Scaling Laws for Neural Language Models - OpenAI's research on how performance scales with size
- RLHF: Training Language Models to Follow Instructions - The InstructGPT paper explaining fine-tuning with human feedback
Practice Exercise
Before moving to the next lesson, try this hands-on experiment:
Temperature Exploration:
- Go to ChatGPT or Claude
- Use the same creative prompt 5 times: "Write the opening sentence of a mystery novel set in a rainy city"
- Note how responses vary
- Try a factual prompt 5 times: "What is the capital of France?"
- Notice the difference in consistency
Reflection Questions:
- When would you want high temperature vs low temperature?
- What types of tasks benefit from consistency?
- What types benefit from variety?
This exercise will cement your understanding of how randomness affects LLM outputs.