Merkle Trees: Implementation in Java and Real-World Applications

The Problem: Verifying Data Without Downloading Everything
Imagine you're using a cryptocurrency wallet on your smartphone. You want to verify that your recent transaction was included in the blockchain, but downloading the entire blockchain—gigabytes of data—would be impractical on a mobile device. How can you be certain your transaction is legitimate without this massive download?
Or consider a peer-to-peer file sharing network where you need to verify that a 10GB file you're downloading hasn't been tampered with, but you want to check each piece as it arrives rather than waiting for the entire download to complete.
These scenarios highlight a fundamental challenge in distributed systems: how to efficiently verify data integrity without processing the entire dataset.
What is a Merkle Tree?
A Merkle Tree (also known as a hash tree) elegantly solves this problem. At its core, it's a tree structure where:
- Every leaf node contains the hash of a data block (like a transaction or file chunk)
- Every non-leaf node contains the hash of its child nodes combined
- The single hash at the top (the root) represents the entire dataset
This hierarchical structure allows you to verify any piece of data with just a small proof—typically log(n) in size—rather than processing the entire dataset.
Why Merkle Trees Matter
Merkle Trees have become foundational in modern distributed systems because they solve three critical problems:
- Data Integrity Verification: Detect any unauthorized changes to any part of a dataset
- Efficient Partial Verification: Prove a specific piece of data exists without revealing the entire dataset
- Consistency Checking: Ensure different parties have identical copies of the same data
These properties make Merkle Trees indispensable in blockchain networks, distributed file systems, peer-to-peer networks, and database systems—anywhere that efficient verification of large datasets is required.
How Merkle Trees Work
Let's break down the structure and operation of a Merkle Tree:
Basic Structure
- Leaf Nodes: Contain hashes of individual data blocks (transactions, files, etc.)
- Internal Nodes: Contain hashes of their child nodes combined
- Root Node: The single hash at the top representing the entire dataset
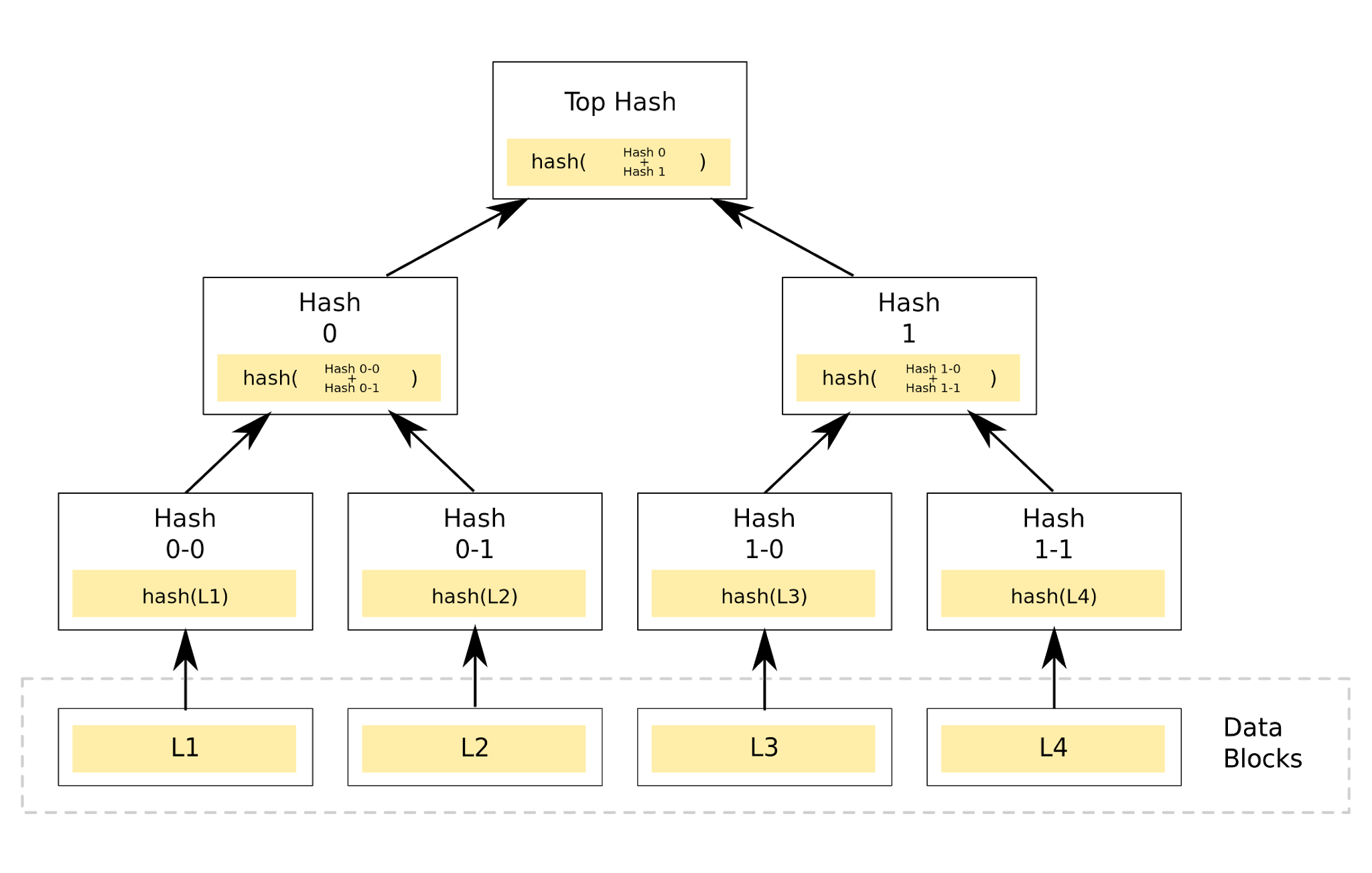
Building a Merkle Tree
Now that we understand the structure, let's walk through how to construct a Merkle Tree from raw data:
- Hash each data block individually to create leaf nodes
- Pair adjacent leaf nodes and hash their combined values to create parent nodes
- Continue pairing and hashing until you reach a single root hash
- If there's an odd number of nodes at any level, duplicate the last node (some implementations)
Merkle Proofs
A Merkle Proof allows verification that a specific data block is part of the tree without revealing the entire tree. It consists of:
- The data block itself
- A set of hashes (typically log(n) in number) needed to reconstruct the path to the root
- The expected root hash for verification
This verification process is what enables lightweight clients to validate transactions without downloading the entire blockchain, or verify file chunks as they arrive in a P2P network.
Java Implementation of Merkle Tree
Now that we understand the theory, let's put it into practice with a robust Java implementation. The following code provides a clean, efficient implementation that handles all the core functionality:
javaimport java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.util.ArrayList; import java.util.List; public class MerkleTree { private Node root; private List<Node> leaves; // Domain separation prefixes private static final byte LEAF_PREFIX = 0x00; private static final byte INTERNAL_PREFIX = 0x01; // Node class representing each node in the Merkle Tree public static class Node { private byte[] hash; private Node left; private Node right; public Node(byte[] hash) { this.hash = hash; } public Node(Node left, Node right) { this.left = left; this.right = right; this.hash = hashChildren(left, right); } public byte[] getHash() { return hash; } } // ProofNode class for position-aware verification public static class ProofNode { private byte[] hash; private boolean isLeftSibling; public ProofNode(byte[] hash, boolean isLeftSibling) { this.hash = hash; this.isLeftSibling = isLeftSibling; } public byte[] getHash() { return hash; } public boolean isLeftSibling() { return isLeftSibling; } } // Constructor that builds the Merkle Tree from a list of data blocks public MerkleTree(List<byte[]> dataBlocks) { constructTree(dataBlocks); } // Build the Merkle Tree private void constructTree(List<byte[]> dataBlocks) { if (dataBlocks.isEmpty()) { throw new IllegalArgumentException("Data blocks must not be empty"); } // Create leaf nodes with domain separation leaves = new ArrayList<>(); for (byte[] block : dataBlocks) { leaves.add(new Node(hashLeaf(block))); } // Handle odd number of leaves by duplicating the last one if (leaves.size() % 2 == 1) { leaves.add(new Node(leaves.get(leaves.size() - 1).getHash())); } // Build the tree from bottom up root = buildTree(leaves); } // Recursive method to build the tree from leaves to root private Node buildTree(List<Node> nodes) { if (nodes.size() == 1) { return nodes.get(0); } List<Node> parents = new ArrayList<>(); // Process nodes in pairs for (int i = 0; i < nodes.size(); i += 2) { Node left = nodes.get(i); Node right = (i + 1 < nodes.size()) ? nodes.get(i + 1) : left; // Duplicate last node if odd parents.add(new Node(left, right)); } return buildTree(parents); } // Hash leaf data with domain separation private static byte[] hashLeaf(byte[] data) { try { MessageDigest digest = MessageDigest.getInstance("SHA-256"); // Prepend leaf prefix for domain separation digest.update(new byte[]{LEAF_PREFIX}); return digest.digest(data); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("Couldn't find SHA-256 algorithm", e); } } // Hash the data using SHA-256 private static byte[] hashData(byte[] data) { try { MessageDigest digest = MessageDigest.getInstance("SHA-256"); return digest.digest(data); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("Couldn't find SHA-256 algorithm", e); } } // Hash two child nodes to create parent node hash with domain separation private static byte[] hashChildren(Node left, Node right) { try { MessageDigest digest = MessageDigest.getInstance("SHA-256"); // Prepend internal node prefix for domain separation digest.update(new byte[]{INTERNAL_PREFIX}); digest.update(left.getHash()); digest.update(right.getHash()); return digest.digest(); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("Couldn't find SHA-256 algorithm", e); } } // Get the Merkle Root hash public byte[] getRootHash() { return root.getHash(); } // Generate a Merkle Proof for a specific leaf node index public List<ProofNode> generateProof(int index) { if (index < 0 || index >= leaves.size()) { throw new IllegalArgumentException("Leaf index out of range"); } List<ProofNode> proof = new ArrayList<>(); generateProofHelper(index, 0, leaves.size() - 1, proof); return proof; } // Helper method for generating the proof private void generateProofHelper(int index, int start, int end, List<ProofNode> proof) { if (start == end) { return; // Reached the leaf node } int mid = (start + end) / 2; if (index <= mid) { // Target is in left subtree, add right sibling to proof proof.add(new ProofNode(getNode(mid + 1, start, end).getHash(), false)); generateProofHelper(index, start, mid, proof); } else { // Target is in right subtree, add left sibling to proof proof.add(new ProofNode(getNode(start, start, mid).getHash(), true)); generateProofHelper(index, mid + 1, end, proof); } } // Helper method to get a node in the tree private Node getNode(int index, int start, int end) { if (start == end) { return leaves.get(index); } int mid = (start + end) / 2; if (index <= mid) { return getNode(index, start, mid); } else { return getNode(index, mid + 1, end); } } // Verify a Merkle Proof public static boolean verifyProof(byte[] leafHash, List<ProofNode> proof, byte[] rootHash) { byte[] computedHash = leafHash; for (ProofNode node : proof) { try { MessageDigest digest = MessageDigest.getInstance("SHA-256"); digest.update(new byte[]{INTERNAL_PREFIX}); // Domain separation for internal nodes if (node.isLeftSibling()) { // If sibling is on the left, concatenate: left + current digest.update(node.getHash()); digest.update(computedHash); } else { // If sibling is on the right, concatenate: current + right digest.update(computedHash); digest.update(node.getHash()); } computedHash = digest.digest(); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("Couldn't find SHA-256 algorithm", e); } } // Check if computed hash matches the expected root hash return MessageDigest.isEqual(computedHash, rootHash); } // Note: This proof generation assumes a perfectly balanced tree and consistent duplication strategy. // For production systems, consider storing parent pointers or building proofs during tree construction. }
Usage Example
To see our Merkle Tree implementation in action, let's create a simple example with four transactions. This demonstrates how to build the tree, generate a proof for a specific transaction, and verify that proof:
javaimport java.nio.charset.StandardCharsets; import java.util.ArrayList; import java.util.List; public class MerkleTreeExample { public static void main(String[] args) { // Create sample data blocks List<byte[]> dataBlocks = new ArrayList<>(); dataBlocks.add("Transaction 1".getBytes(StandardCharsets.UTF_8)); dataBlocks.add("Transaction 2".getBytes(StandardCharsets.UTF_8)); dataBlocks.add("Transaction 3".getBytes(StandardCharsets.UTF_8)); dataBlocks.add("Transaction 4".getBytes(StandardCharsets.UTF_8)); // Build Merkle Tree MerkleTree merkleTree = new MerkleTree(dataBlocks); // Get root hash byte[] rootHash = merkleTree.getRootHash(); System.out.println("Root Hash: " + bytesToHex(rootHash)); // Generate proof for Transaction 2 (index 1) List<MerkleTree.ProofNode> proof = merkleTree.generateProof(1); System.out.println("Proof size: " + proof.size()); // Verify the proof byte[] transaction2Hash = MerkleTree.hashLeaf("Transaction 2".getBytes(StandardCharsets.UTF_8)); boolean isValid = MerkleTree.verifyProof(transaction2Hash, proof, rootHash); System.out.println("Proof verification: " + isValid); } // Helper method to convert bytes to hex string private static String bytesToHex(byte[] bytes) { StringBuilder result = new StringBuilder(); for (byte b : bytes) { result.append(String.format("%02x", b)); } return result.toString(); } }
With our implementation complete, you can see how Merkle Trees provide an elegant solution for data verification. But how are they used in production systems? Let's explore some of the most important real-world applications where this data structure has become essential.
Real-World Applications of Merkle Trees
The elegance and efficiency of Merkle Trees have made them foundational components in many modern systems. Here's how they're being used in production environments:
1. Blockchain Technology
Merkle Trees are a fundamental component of blockchain architectures:
Bitcoin and Cryptocurrencies:
- Bitcoin uses Merkle Trees to efficiently organize transactions in blocks
- The Merkle root is included in the block header, allowing lightweight clients to verify transactions without downloading the entire blockchain
- This enables Simplified Payment Verification (SPV) where mobile wallets can operate without storing the full blockchain
Implementation Detail: In Bitcoin, all transactions in a block are hashed together using a Merkle Tree. The resulting Merkle root is only 32 bytes regardless of how many transactions are in the block (which could be thousands). This compact representation allows efficient verification while maintaining security.
2. Distributed File Systems
IPFS (InterPlanetary File System):
- Uses Merkle DAGs (Directed Acyclic Graphs), an extension of Merkle Trees
- Enables content-addressed storage where files are retrieved by their content hash rather than location
- Allows for deduplication of data across the network
- Provides integrity verification for distributed file storage
Practical Example: When you add a file to IPFS, it's split into blocks, each block is hashed, and these hashes are organized in a Merkle Tree. The root hash becomes the Content Identifier (CID) that uniquely identifies that file. If any part of the file changes, the CID changes, ensuring data integrity.
3. Database Systems
Distributed Databases:
- Cassandra and other NoSQL databases use Merkle Trees for anti-entropy and data synchronization
- Nodes can efficiently compare data sets and identify differences without transferring entire datasets
- Enables efficient repair of inconsistent data across replicas
Implementation Detail: In Cassandra, each node builds a Merkle Tree of its data. When nodes need to synchronize, they compare their Merkle Trees starting from the root. If the roots match, no synchronization is needed. If they differ, they traverse down the tree to identify exactly which data blocks need to be synchronized, minimizing data transfer.
4. Certificate Transparency
SSL/TLS Certificate Verification:
- Google's Certificate Transparency uses Merkle Trees to create an append-only, publicly auditable log of all SSL certificates
- Enables detection of fraudulently issued certificates
- Allows website owners to monitor certificates issued for their domains
How It Works: Certificate authorities submit new certificates to transparency logs. These logs organize certificates in Merkle Trees and provide cryptographic proof that a specific certificate is included in the log. This allows browsers and security tools to verify that certificates are publicly logged and not secretly issued.
5. Peer-to-Peer Networks
BitTorrent Protocol:
- Uses Merkle Trees to verify the integrity of downloaded file pieces
- Allows peers to verify chunks of data independently
- Prevents malicious peers from distributing corrupted data
Practical Application: When downloading a large file via BitTorrent, the file is split into pieces. The Merkle Tree allows you to verify each piece as it arrives rather than waiting for the entire file. If a piece fails verification, it can be requested again from a different peer.
6. Git Version Control
Git's Object Model:
- While not a traditional Merkle Tree, Git's commit history forms a Merkle DAG
- Each commit contains a hash of its parent commit(s) and the project state
- This creates a tamper-evident history where changing any file in any commit would change all subsequent commit hashes
Implementation Detail: In Git, changing a file in an old commit would change that commit's hash, which would change its child commit's hash, and so on up to the latest commit. This makes it immediately obvious if someone attempts to alter the project history.
Advanced Concepts and Optimizations
Sparse Merkle Trees
Sparse Merkle Trees are a variant optimized for scenarios where you have a very large potential key space but only a small subset of keys are actually used:
- Pre-allocates a tree with a position for every possible key (e.g., all 2^256 possible keys)
- Most nodes contain default values (typically zero hashes)
- Optimized implementations avoid storing the empty parts of the tree
- Used in Ethereum for storing the state trie
Merkle Mountain Ranges
Merkle Mountain Ranges (MMRs) are an append-only variant of Merkle Trees that efficiently handle growing datasets:
- Optimized for append-only data structures
- Allows efficient addition of new leaves without rebuilding the entire tree
- Used in cryptocurrencies like Grin and Beam
Incremental Merkle Trees
Incremental Merkle Trees allow efficient updates without rebuilding the entire tree:
- Maintain additional state to allow efficient updates
- Used in privacy-focused cryptocurrencies like Zcash
- Enable efficient generation of zero-knowledge proofs
Performance Considerations
As with any data structure, understanding the performance characteristics of Merkle Trees is crucial when implementing them in production systems. Let's examine the key factors that affect their efficiency:
Time Complexity
- Tree Construction: O(n) where n is the number of data blocks
- Proof Generation: O(log n)
- Proof Verification: O(log n)
Space Complexity
- Full Tree Storage: O(n)
- Proof Size: O(log n)
Optimization Techniques
- Caching Intermediate Nodes: Store frequently accessed nodes to avoid recalculation
- Parallel Hashing: Use multiple threads for hashing operations in large trees
- Lazy Evaluation: Only compute hashes when needed
- Optimized Hash Functions: Choose hash functions based on your security and performance requirements
Common Pitfalls
When implementing Merkle Trees in production systems, be aware of these common mistakes:
-
Inconsistent Left/Right Concatenation Order: Not defining a consistent order for concatenating child hashes can lead to different root hashes for the same data across systems
-
Missing Domain Separation: Failing to distinguish between leaf and internal node hashes can create security vulnerabilities through second-preimage attacks
-
Raw Concatenation Without Length Prefixing: Simple concatenation can lead to ambiguity (e.g., concatenating "ab" and "c" produces the same result as concatenating "a" and "bc")
-
Inconsistent Handling of Odd Nodes: Different strategies for handling odd numbers of nodes can lead to incompatible implementations
-
Ambiguous Proof Verification: Not encoding the direction (left/right) in Merkle proofs makes verification impossible to perform correctly
-
Insufficient Testing of Edge Cases: Not testing empty trees, single-node trees, or trees with odd numbers of nodes
-
Ignoring Tree Balancing: Unbalanced trees can lead to inefficient proofs and vulnerabilities
-
Relying on Hash Function Properties: Assuming specific hash function behavior that might not be guaranteed across all implementations
Conclusion
From our journey through theory, implementation, and real-world applications, it's clear why Merkle Trees have become so fundamental in modern computing. Their elegant design solves a critical problem: how to efficiently verify data integrity in distributed systems without requiring complete datasets.
From blockchains to distributed file systems, from database synchronization to secure version control, Merkle Trees continue to enable new applications that require efficient, secure data verification.
In this guide we went from theory to a concrete Java implementation, real-world production use cases, and even advanced variants like Sparse and Incremental Merkle Trees — which is exactly the progression you'll face when designing real systems. By understanding not just the basic structure but also the implementation details, common pitfalls, and optimization techniques, you're now equipped to apply this powerful data structure in your own projects.
As distributed systems become increasingly prevalent, understanding Merkle Trees and their variants becomes essential knowledge for software engineers working on cutting-edge applications. Whether you're building the next blockchain platform, designing a distributed database, or creating a peer-to-peer file sharing system, Merkle Trees provide a powerful tool for ensuring data integrity and efficient verification.
Further Reading
Related Posts
Continue exploring similar topics

Implementing Trie (Prefix Tree): A Complete Guide with Java
Learn how to implement a Trie data structure in Java with insert, search, delete, and prefix matching operations for efficient string processing and autocomplete functionality.

Spring Boot 3.x: What Actually Changed (and What Matters)
A practical look at Spring Boot 3.x features that change how you build services - virtual threads, reactive patterns, security gotchas, and performance lessons from production.

Java Multithreading Coding Questions for Interviews: Classic Problems and Solutions
Master the most common multithreading interview questions including Producer-Consumer, Dining Philosophers, and FizzBuzz problems with practical Java implementations.